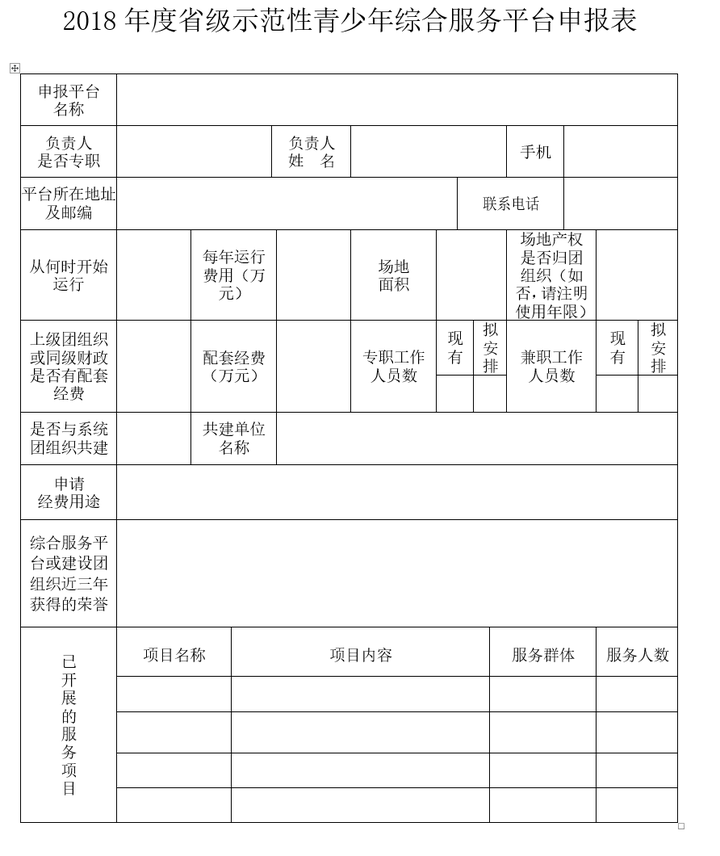
这两天用docx提取Word中表格时, 发现对于稍稍复杂一点的表格就会出现很多重复项, 比如
使用代码
table_temp = []
path = r"./demo.docx"
document = Document(path)
tables = document.tables
for row in tables[0].rows:
row_temp = []
for cell in row.cells:
row_temp.append(cell.text)
table_temp.append(row_temp)
table_temp其得到结果部分为
['从何时开始\n运行',
'\n\n2017.10',
'每年运行费用(万元)',
'每年运行费用(万元)',
'每年运行费用(万元)',
'\n\n2',
'场地\n面积',
'600㎡',
'600㎡',
'600㎡',
'600㎡',
'场地产权是否归团组织(如否,请注明使用年限)',
'场地产权是否归团组织(如否,请注明使用年限)',
'场地产权是否归团组织(如否,请注明使用年限)',
'是',
'是'],
['上级团组织或同级财政是否有配套经费',
'无',
'配套经费\n(万元)',
'配套经费\n(万元)',
'配套经费\n(万元)',
'',
'专职工作人员数',
'现有',
'现有',
'拟安排',
'拟安排',
'兼职工作人员数',
'兼职工作人员数',
'兼职工作人员数',
'现有',
'拟安排'],
['上级团组织或同级财政是否有配套经费',
'无',
'配套经费\n(万元)',
'配套经费\n(万元)',
'配套经费\n(万元)',
'',
'专职工作人员数',
最初我试图跳过已出现的文本, 但是有不少文本本来就是多次出现的, 遂作罢.
之后阅读了部分源代码发现, 那些程序性重复文本是对同一个对象的引用, 所以只要在读取一个值后对其text置空或者任意自定义的其他, 就可以把后面将要出现的程序性重复项也设置为自定义项.
即
table_temp = []
path = r"demo.docx"
null_text = str(time.time())
document = Document(path)
tables = document.tables
for row in tables[0].rows:
row_temp = []
for cell in row.cells:
if cell.text != null_text:
row_temp.append(cell.text)
cell.text = null_text
table_temp.append(row_temp)
table_temp可得到
[['申报平台\n名称'],
['负责人\n是否专职', '负责人\n姓 名', '手机'],
['平台所在地址及邮编', '联系电话 '],
['从何时开始\n运行', '每年运行费用(万元)', '场地\n面积', '场地产权是否归团组织(如否,请注明使用年限)'],
['上级团组织或同级财政是否有配套经费',
'配套经费\n(万元)',
'专职工作人员数',
'现有',
'拟安排',
'兼职工作人员数',
'现有',
'拟安排'],
[],
['是否与系统团组织共建', '共建单位名称'],
['申请\n经费用途'],
['综合服务平台或建设团组织近三年获得的荣誉'],
['已\n开\n展\n的\n服\n务\n项\n目', '项目名称', '项目内容', '服务群体', '服务人数']]
至此, 只要稍稍处理下规则就能愉快地格式化数据了
吐槽:
docx对于表格的处理真的太麻缠了, 几乎要被逼换vba, QWQ
从我的知乎文章搬运而来